云计算(Cloud Computing)是一种基于因特网的超级计算模式,在远程的数据中心里,成千上万台电脑和服务器连接成一片电脑云。用户通过电脑、笔记本、手机等方式接人数据中心,按自己的需求进行运算。目前,对于云计算仍没有普遍一致的定义。结合上述定义,可以总结出云计算的一些本质特征,即分布式计算和存储特性、高扩展性、用户友好性、良好的管理性。
1云存储架构图
橘色的作为存储节点(Storage Node)负责存放文件,蓝色作为控制节点((Control Node)则是负责文件索引,并负责监控存储节点间容量及负载的均衡,这两个部分合起来便组成一个云存储。存储节点与控制节点都是单纯的服务器,只是存储节点的硬盘多一些,存储节点服务器不需要具备RAID的功能,只要能安装Linux即可,控制节点为了保护数据,需要有简单的RAID level O1的功能。
云存储不是要取代现有的盘阵,而是为了应付高速成长的数据量与带宽而产生的新形态存储系统,因此云存储在设计时通常会考虑以下三点:
(1)容量、带宽的扩容是否简便
扩容是不能停机,会自动将新的存储节点容量纳入原来的存储池。不需要做繁复的设定。
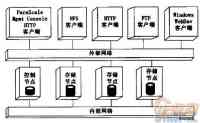
图1云存储架构图
(2)带宽是否线形增长
使用云存储的客户,很多是考虑未来带宽的增长,因此云存储产品设计的好坏会产生很大的差异,有些十几个节点便达到饱和,这样对未来带宽的扩容就有不利的影响,这一点要事先弄清楚,否则等到发现不符合需求时,已经买了几百TB,后悔就来不及了。
(3)管理是否容易。
2云存储关键技术
云存储必须具备九大要素:①性能;②安全性;③自动ILM存储;④存储访问模式;⑤可用性;⑥主数据保护;⑦次级数据保护;⑧存储的灵活;⑨存储报表。
云计算的发展离不开虚拟化、并行计算、分布式计算等核心技术的发展成熟。下面对其介绍如下:
(1)集群技术、网格技术和分布式文件系统
云存储系统是一个多存储设备、多应用、多服务协同工作的集合体,任何一个单点的存储系统都不是云存储。
既然是由多个存储设备构成的,不同存储设备之间就需要通过集群技术、分布式文件系统和网格计算等技术,实现多个存储设备之间的协同工作,使多个的存 储设备可以对外提供同一种服务,并提供更大更强更好的数据访问性能。如果没有这些技术的存在,云存储就不可能真正实现,所谓的云存储只能是一个一个的独立 系统,不能形成云状结构。
(2)CDN内容分发、P2P技术、数据压缩技术、重复数据删除技术、数据加密技术
CDN内容分发系统、数据加密技术保证云存储中的数据不会被未授权的用户所访问,同时,通过各种数据备份和容灾技术保证云存储中的数据不会丢失,保证云存储自身的安全和稳定。如果云存储中的数据安全得不到保证,也没有人敢用云存储了。
(3)存储虚拟化技术、存储网络化管理技术
云存储中的存储设备数量庞大且分布多在不同地域,如何实现不同厂商、不同型号甚至于不同类型(例如FC存储和IP存储)的多台设备之间的逻辑卷管 理、存储虚拟化管理和多链路冗余管理将会是一个巨大的难题,这个问题得不到解决,存储设备就会是整个云存储系统的性能瓶颈,结构上也无法形成一个整体,而 且还会带来后期容量和性能扩展难等问题。
3部署Hadoop
从历史上看,数据分析软件面对当今的海量数据已显得力不从心,这种局面正在悄然转变。新的海量数据分析引擎已经出现。例如Apache的Hadoop,实践证明,Hadoop在数据处理方面是做得最好的且是开源的平台之一。
云存储中心是由大量服务器构成Hadoop的数据节点((DataNodes),负责保存文件的内容,实现文件的分布式存储、负载平衡以及文件的容错控制。
下面将利用Hadoop作为实验平台,一步一步演示如何部署一个三个节点的集群,并测试一下MapRe-dace分布式处理的强大功能,在Hadoop分布式文件系统(HDFS)中存人两个文件,并采用MapReduce计算出两个namelist文件中各个名字出现的次数,程序架构设计如图2所示。
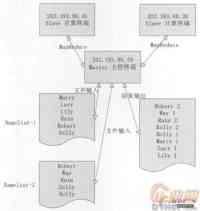
图2 3个节点的Hadoop集群
其中NameNode主节点和DataNode从节点的分布情况如下:
表1

(1)启动Hadoop集群
只需要在NameNode主节点上执行start-all.sh命令即可,同时Master节点可以通过ssh登录到各,lave节点去启动其他相关进程。

(2) MapRudce测试
在NameNode和DataNode两个结点都运行正常的时候,也就是Hadoop部署成功了之后,我们在NameNode主节点上准备两个名单文件。名单文件的内容如下:

4运行实验及结果

5结语
结果跟我们预期的一样,这样在以Hadoop为平台进行了对HDFS的文件存储,并且统计了文件中数据的数量,然后显示出来。
猜您喜欢:
1.hadoop伪分布式安装方法
2.Hadoop读写文件时内部工作机制是怎样的?
3.Hadoop中的一些基本操作
XSKY开发了基于对象存储XEOS的专用Hadoop HDFS高性能客户端XSKY HDFS Client。
原先支持Hadoop的四大商业机构纷纷宣布支持Spark,包含知名Hadoop解决方案供应商Cloudera和知名的Hadoop供应商MapR。
证券交易数据属于典型的结构化数据,采用Sql on Hadoop[1]技术,既可用廉价PC服务器获得良好的容量线性扩展能力,又可提供便于统计分析的SQL接口方便数据应用开发。
本文总结Hadoop十个认识误区,帮助大家更好地理解和学习Hadoop。由于Hadoop本身是由并行运算架构(MapReduce)与分布式文件系统(HDFS)所组成,所以我们也看到很多研究机构或教育单位,开始尝试把部分原本执行在HPC 或Grid上面的任务
数据产生后,意味着数据的采集工作已经完成,那么数据的输入与有效输出问题怎么破解?
【聚焦搜索,数智采购】2021第一届百度爱采购数智大会即将于5月28日在上海盛大开启!
本次大会上,紫晶存储董事、总经理钟国裕作为公司代表,与中国―东盟信息港签署合作协议
XEUS统一存储已成功承载宣武医院PACS系统近5年的历史数据迁移,为支持各业务科室蓬勃扩张的数据增量和访问、调用乃至分析需求奠定了坚实基础。
大兆科技全方面展示大兆科技在医疗信息化建设中数据存储系统方面取得的成就。
双方相信,通过本次合作,能够使双方进一步提升技术实力、提升产品品质及服务质量,为客户创造更大价值。










